🔷 Introduction
Cloud cost is one of the biggest challenges in large-scale platforms:
Kubernetes clusters running 24×7
Multi-tenant workloads
Batch simulations
Airflow jobs
SDV/Digital Twin environments
CI/CD pipelines
High-memory or GPU workloads
Growing storage and logs
Companies often spend 30–60% more than necessary due to poor visibility and lack of structured cost governance.
This guide explains how to optimize cloud, Kubernetes, and SDV workloads using proven architectures, FinOps practices, and real-world implementation patterns used by top enterprises.
🔷 1. Why Cloud Costs Spiral Out of Control
❌ Over-provisioned workloads
Developers request:
❌ Unused resources
Idle pods
Orphaned volumes
Unused load balancers
Old EBS/PVC
❌ CI/CD running unnecessary jobs
Dozens of pipelines triggered by every commit.
❌ Wrong storage tiers
Premium SSD vs Standard HDD where not needed.
❌ Logs consuming 2TB+
Raw logs stored with no TTL policies.
❌ GPU nodes always running
Even when no one uses them.
This is where cost optimization becomes vital.
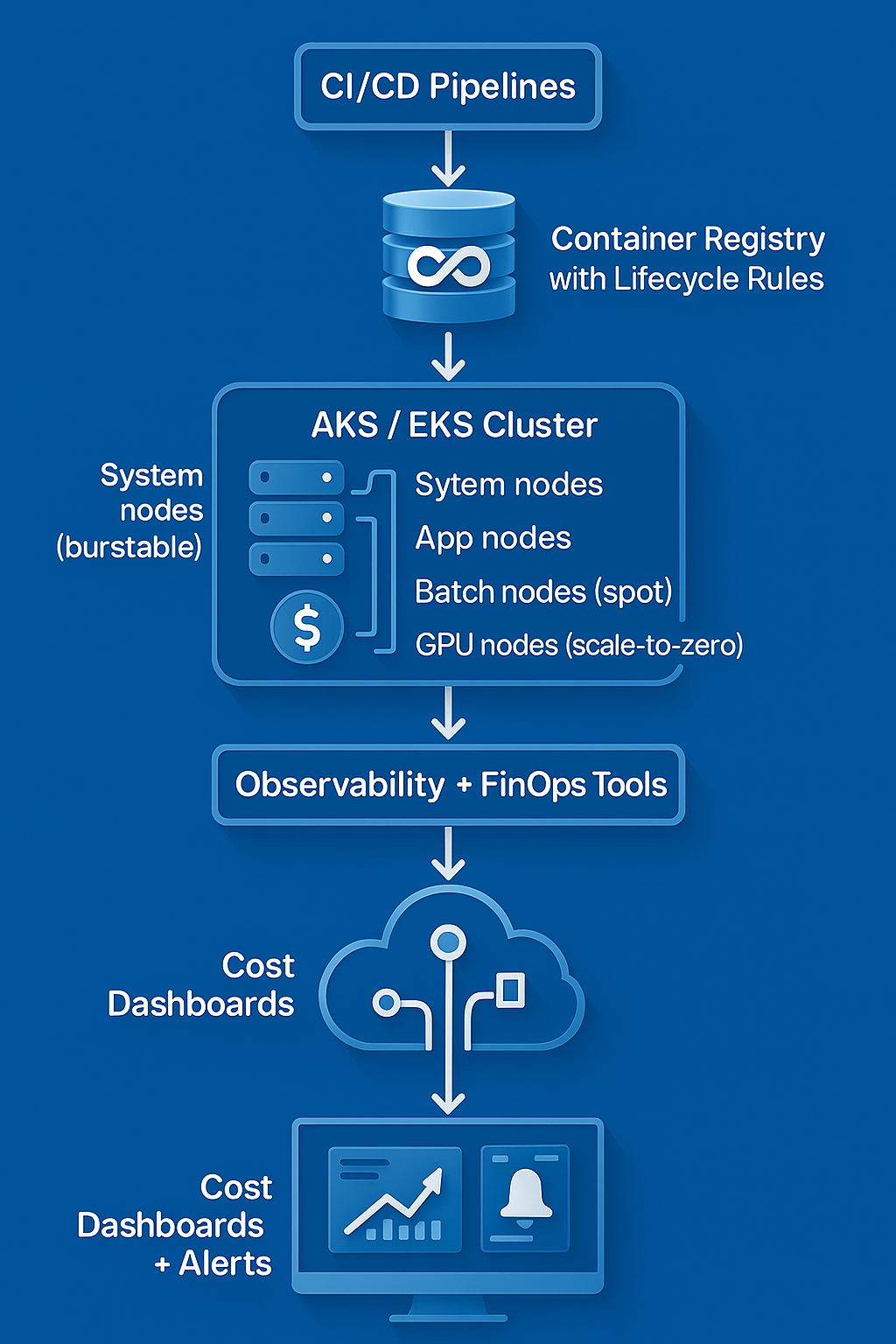
🔷 2. Reference Cost-Optimized Cloud Architecture
A real-world, cost-aware architecture:
🔷 3. Step-by-Step Implementation Guide
⭐ STEP 1 — Enable Kubernetes Autoscaling the Right Way
Use:
Example:
Best Practices:
⭐ STEP 2 — Implement Spot Nodes for Non-Critical Workloads
Spot nodes can reduce compute cost by 70–90%.
Use spot nodepools for:
Simulations
Batch jobs
CI runners
Non-critical APIs
Best Architecture:
⭐ STEP 3 — Right-Size Pods Using Metrics
Find actual usage via:
Kube-state-metrics
Prometheus
Metrics-server
vpa-recommender
Example:
If actual usage =
CPU: 120m
Memory: 200Mi
Set requests:
CPU: 150m
Memory: 256Mi
Avoid:
This alone saves thousands of dollars monthly.
⭐ STEP 4 — Implement TTL Policies for PVC, Logs & Artifacts
Storage TTL:
Delete unused PVC > 30 days
Auto-delete completed-job PVs
Cleanup old simulation logs
Container registry TTL:
Log TTL:
⭐ STEP 5 — Use “Scale-to-Zero” for GPU & High-Compute Nodes
GPU nodes cost extremely high.
Implement:
A nodepool with:
Only charges when workloads exist.
⭐ STEP 6 — Use FinOps Dashboards for Visibility
Dashboards via:
Grafana
Azure Cost Management
AWS Cost Explorer
KubeCost
Prometheus-exporters
Track:
Cost per namespace
Cost per workload
Idle CPU
Cost per tenant/team
Storage cost
Egress cost
FinOps makes cost visible to developers — not just DevOps.
⭐ STEP 7 — Optimize CI/CD Pipelines
CI/CD often consumes 35–45% of cloud compute.
Optimize by:
Parallelizing only where necessary
Cancelling old pipeline runs
Caching dependencies
Scaling CI runners on spot VMs
Reusing artifacts
Reducing pipeline triggers
Example Optimization:
Cancel previous runs if new commit arrives:
⭐ STEP 8 — Use Multi-Tenant Cost Allocation
For SDV / DevOps platforms:
Example quotas:
⭐ STEP 9 — Implement Pod Disruption Budgets (PDBs)
PDB allows APIs to run on spot nodes without downtime:
⭐ STEP 10 — Optimize Network & Load Balancer Costs
LB Best Practices:
Use internal LBs
Use ingress controllers
Minimize standalone LBs
Use Azure Private Link
Egress optimization:
🔷 4. Real-World Cost Optimization Scenario
Scenario: SDV Simulation Cluster Costs Too High
Symptoms:
Fixes:
GPU nodepool → scale-to-zero
Storage TTL → delete > 14 days
Separate spot nodepool for simulations
Add cancellation logic in CI
Use vpa-recommender for right-sizing
Savings: ~45% monthly.
🔷 5. Cost Optimization Best Practices
Kubernetes
✔ Always use autoscaling
✔ Right-size everything
✔ No static replicas
✔ Delete orphaned resources
Storage
✔ Move logs to cheaper storage
✔ Enable TTL policies
✔ Compress simulation logs
CI/CD
✔ Limit triggers
✔ Use spot runners
✔ Cache everything
Governance
✔ Monthly cost review
✔ Dashboards per team
✔ Alerts for spikes
🔷 6. Common Anti-Patterns
❌ Using on-demand nodes everywhere
❌ Keeping 1000s of logs forever
❌ High CPU/memory requests
❌ No namespace-level budgeting
❌ Using GPUs for small tasks
❌ No cluster autoscaling
Fix these and cost automatically drops.
🔷 Conclusion
Cost optimization is not a one-time task — it is a continuous engineering discipline.
With the right architecture:
Kubernetes becomes efficient
CI/CD cost drops dramatically
SDV simulations become predictable
Cloud bills stabilize
Engineering productivity increases
A mature cost strategy transforms cloud from a liability into a powerful enabler.